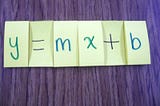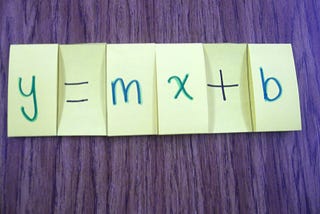Adina SteinmanBuilding a Tableau DashboardSo far, I have covered various topics involving data collection, data mining, data processing and machine learning. While all of these…Jul 29, 2021Jul 29, 2021
Adina SteinmanWhy I chose Flatiron SchoolBetween all of my technical-oriented posts, I thought it would be beneficial to speak a little about myself and my choice for pursuing the…May 27, 2021May 27, 2021
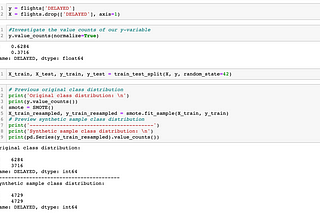
Adina SteinmanDealing with Class ImbalanceOftentimes in Machine Learning, you are working towards solving a classification problem. For example, will someone default on their credit…May 19, 2021May 19, 2021
Adina SteinmanIntro to SQL: A Beginner’s GuideSQL is a powerful tool that is used amongst data analysts and scientists in the tech industry. Building a repertoire that includes both SQL…May 12, 2021May 12, 2021
Adina SteinmanFinding the Perfect Playlist for YouNetflix, Spotify, Facebook and many other platforms have powerful algorithms and tools that target specific advertising to their users…Apr 5, 2021Apr 5, 2021
Adina SteinmanBuilding A Collaborative-Filtering Recommendation System in SurpriseMany companies use collaborative filtering recommendation systems. For example, Dick’s Sporting Goods’ message in the image above makes…Jan 28, 20211Jan 28, 20211
Adina SteinmanGuide to Fitting, Predicting and Creating Functions for Machine Learning ModelsIn the world of data science, there are a variety of machine learning models at a data scientists’ disposal. Often, we are presented with…Dec 25, 2020Dec 25, 2020
Adina SteinmanAnalyzing a Linear Regression ResultIn statistics, a common tool is to build a linear regression model. As a data scientist, it is easy to get caught up in the technical…Nov 30, 2020Nov 30, 2020
Adina SteinmanNavigating my first API: the TMDb DatabaseThe TMDb Database is a powerful, easy-to-use API. New to the world of APIs? Read below for some tips on how to get started!Oct 22, 2020Oct 22, 2020